Summary for Q1/2024
Here is the scorecard of MySql (left) and MongoDB (right) vs. Postgres (100%), not on the card. The arrows show the trend vs. Postgres.
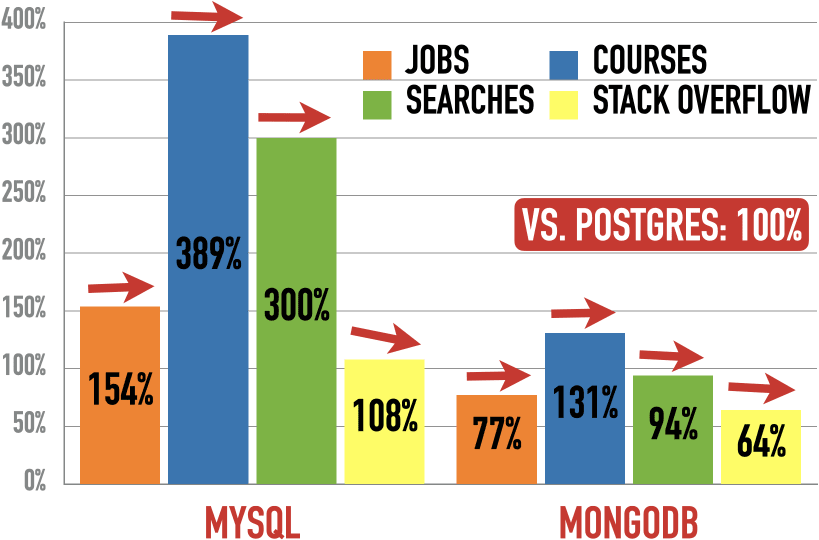
MySQL and MongoDB gain jobs on Postgres. MySQL loses slightly in courses, holds steady in searches, and drops more heavily in Stack Overflow questions. MongoDB holds steady in courses but loses slightly in searches and Stack Overflow questions.
These are my recommendations:
- On your current project, keep your existing database unless that database is absolutely, irrevocably, really not working out for you.
- If you need to switch databases or are on a new project:
- If you know that you’ll need the NoSQL features and/or scalability, and you can’t get this with MySQL, then use MongoDB.
- Otherwise, use MySQL.
Archive
| 2023 | Q4 | Q3 | Q2 | Q1 | ||||
| 2022 | Q4 | Q3 | Jun | May | Apr | Mar | Feb | Jan |
| 2021 | Dec | Nov |
Table Of Contents
Choices
Here are the choices in alphabetical order:
- Apache Cassandra
- Couchbase
- MongoDB
- Oracle’s MySQL
- Neo4j
- Postgres (“PostgreSQL” is the correct but longer name)
I’m only listing open-source products here. I don’t include commercial databases (like Oracle or Microsoft SQL Server) or cloud-proprietary databases (like Amazon DynamoDB or Google Cloud Spanner). Why?
For commercial and cloud products, many other factors play a role in deciding for or against a product - money, legal considerations, existing contracts, vendor relations, etc. Restricting myself to open-source products means limiting myself to only technical concerns - or so I hope.
I also have little production experience with NoSQL databases. So, I looked at the databases that Spring Data supports and picked what I think are the generally applicable NoSQL databases. Please tell me if I picked the wrong ones here!
Popularity
Why Popularity - and How?
Picking a popular technology makes our developer life easier: Easier to learn, easier to build, debug & deploy, easier to find jobs/hire, and easier to convince teammates & bosses. Popularity can make a difference in two situations: When multiple technologies score similarly, we could go for the most popular one. And when a technology is very unpopular, we may not use it.
I measure popularity among employers and developers as the trend between competing technologies. I count mentions in job ads at Indeed for employer popularity. For developer popularity, I use Google searches, Udemy course buyers, and Stack Overflow questions.
Employers: Job Ads
The Indeed job search is active in 62 countries. I picked 59 countries representing 69% of the worldwide GDP in 2022, excluding three countries because English word searches proved ineffective there: China, Japan, and South Korea. Job searches demonstrate the willingness of organizations to pay for a technology - the strongest indicator of popularity in my mind. Postgres is the baseline.
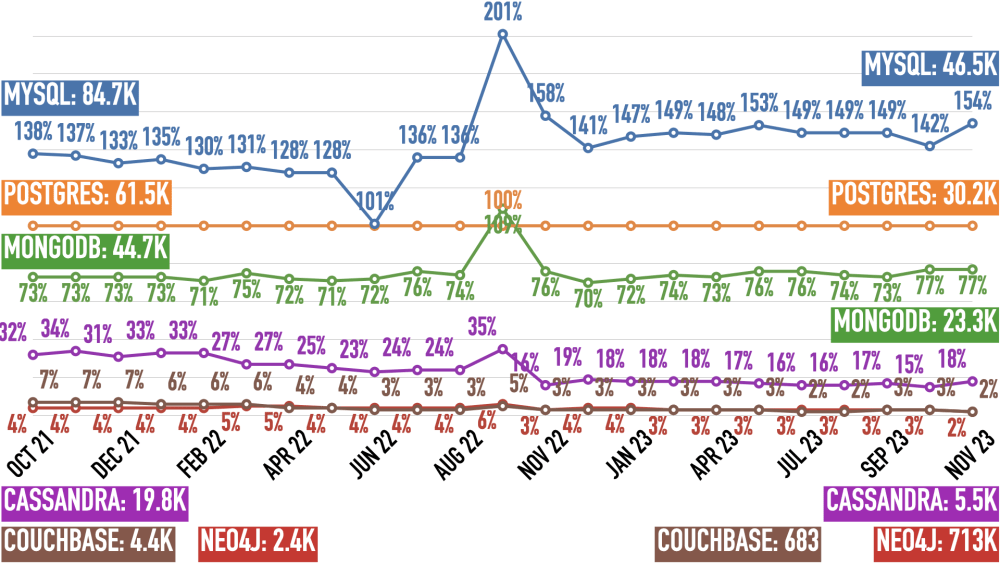
There are no job numbers for February 2023 because I made a mistake collecting them. There are no job numbers for May and December 2023, either, because of changes on the Indeed websites.
MySQL wins, Postgres is second, and MongoDB is third. MySQL is now 12% higher than in October 2021, leading Postgres 1.5:1. MongoDB is up 5% from October 2021. Cassandra, Couchbase, and lost about half of their mentions since October 2021.
Comparing November 2023 vs. November 2022, job ads are down 32%.
Please see here for details, caveats, and adjustments to the job ad mentions.
You can find the detailed search results with links here. They include breakdowns by continents:
Developers
Students at Udemy
Udemy is one of the biggest online learning sites. They publish the number of people who bought a course (beyond a certain threshold, possibly around 100k). This shows how many people evaluate a technology. MongoDB is the baseline. Cassandra, Couchbase, and Neo4j haven’t crossed Udemy’s reporting threshold (possibly around 100,000 students).
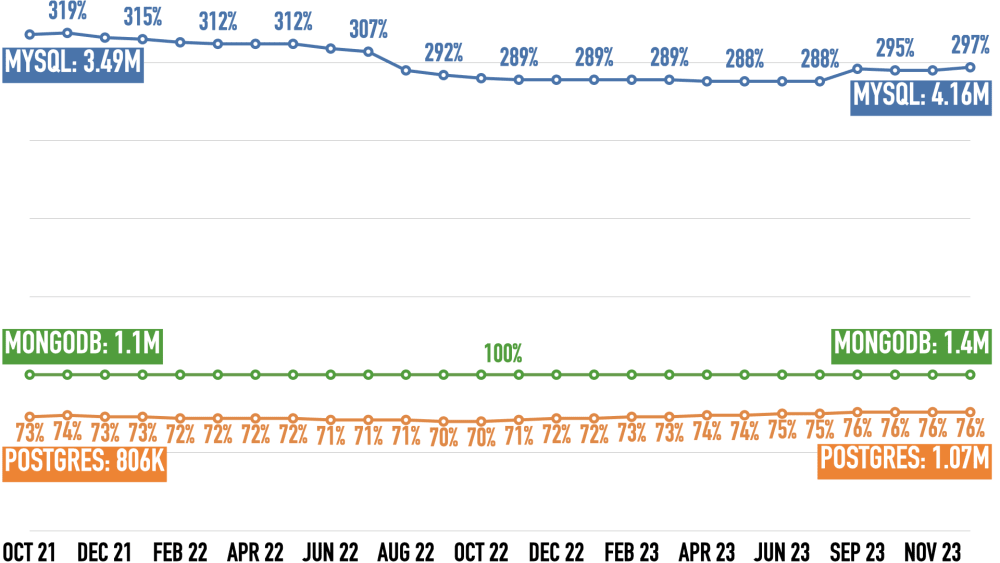
MySQL wins, MongoDB places second, and Postgres is third. MySQL leads MongoDB 3:1 and just had a big jump. After losing share to MongoDB for the first year, Postgres is up slightly in the second year, having three quarters of MongoDB’s students.
Here are the links that show the courses for all and the number of students for some:
Google Searches
Google Trends demonstrates the initial interest in a technology over time. “More searches = better” to me. The percentage behind the current value is the drop-off from the peak value, marked with a circle.
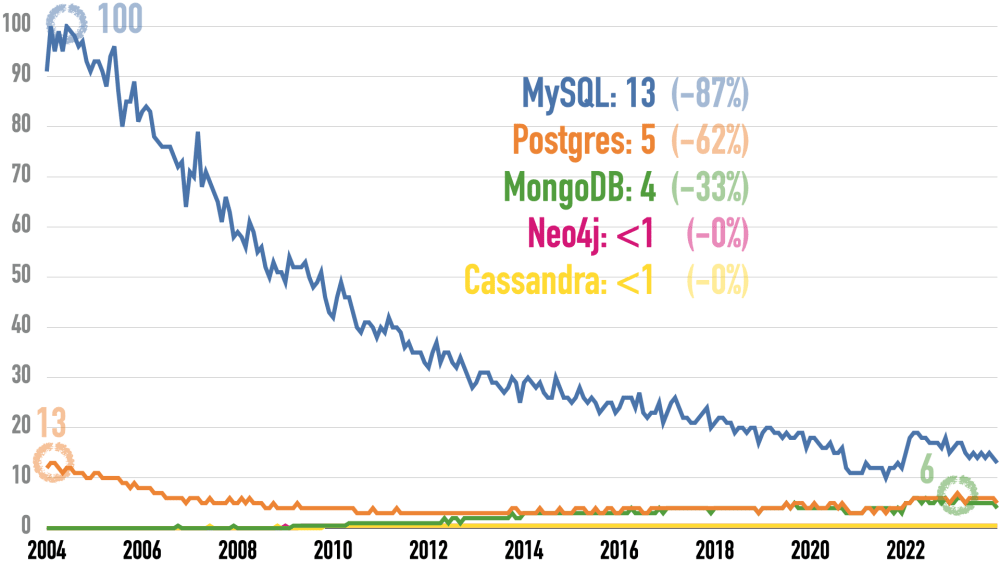
Google changed its measurement algorithms on January 1, 2016, and January 1, 2022. That caused spikes for all values, especially in 2022.
This link produces the chart above. Google Trends only allows five choices, so here’s Couchbase instead of Neo4j – it doesn’t make a difference to the overall picture.
Like Java, MySQL still leads the pack at 1/7 of its peak popularity from 2004. Unlike Java, MySQL’s competitors caught up more: Postgres and MongoDB have a third of MySQL’s volume.
Let’s zoom in on the last three years (chart link):
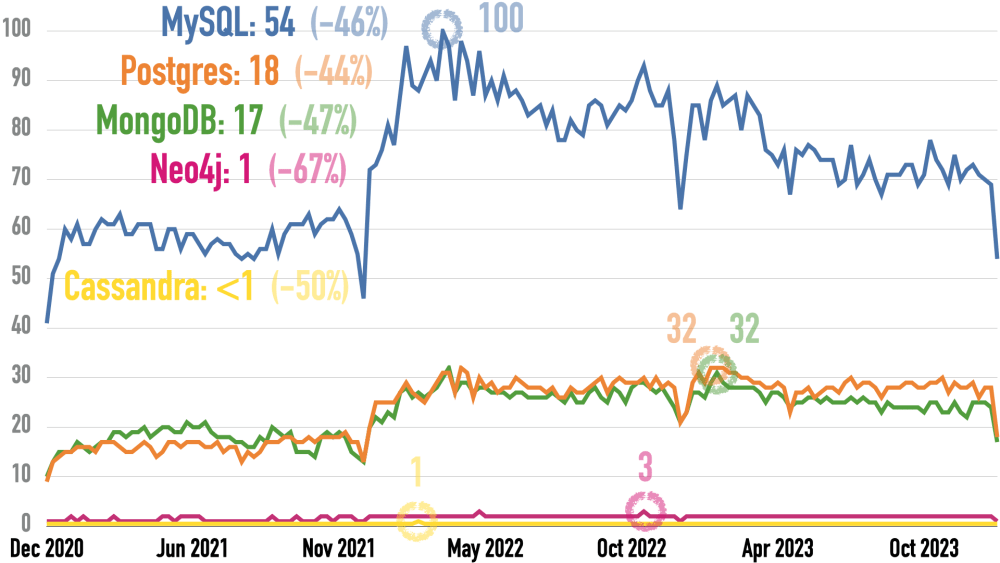
Google changed its measurement algorithms on January 1, 2022. That caused spikes for all values.
MySQL wins, Postgres is second, and MongoDB is third. Google searches always decline in December. At 54, MySQL is only slightly above where it started three years ago. Still, it leads Postgres 2.4:1. Postgres and MongoDB have moved nearly identically for the last three years, with Postgres pulling away a bit before the December decliine. Neo4j and Cassandra are both flat, barely above zero.
Here’s the link with Couchbase instead of Neo4j – it also hovers barely above zero, just like Neo4j.
Monthly Questions at Stack Overflow
We can run database queries against the questions, answers, and comments at Stack Overflow with the StackExchange Data Explorer. The number of monthly questions is a proxy for using a technology during evaluation and productive use. This number includes deleted questions to be more accurate, as Stack Overflow automatically deletes questions without answers after a year. “More questions = better” to me. The percentage behind the current value is the drop-off from the peak value, marked with a circle.
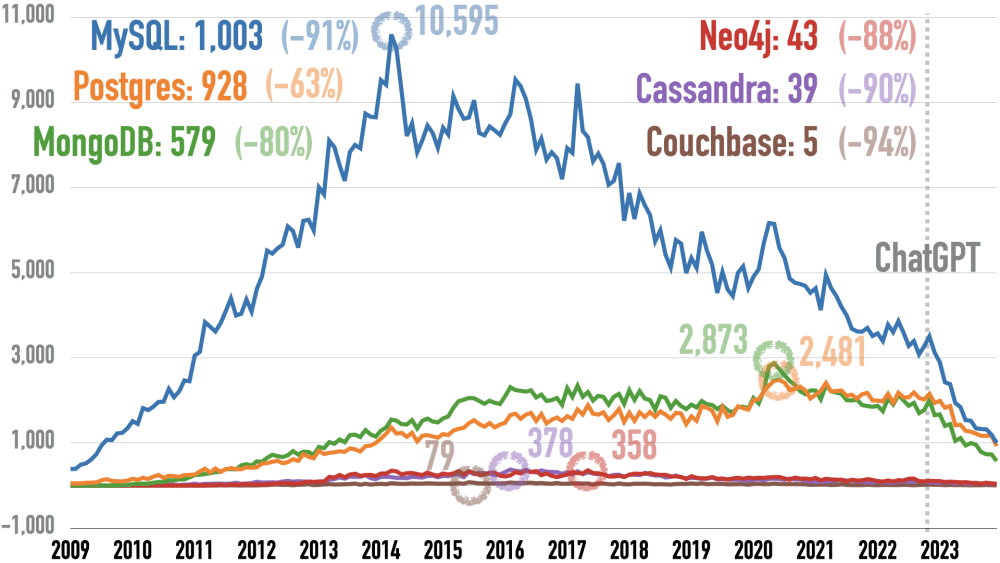
Postgres wins, MySQL is second, and MongoDB is third. MySQL is slightly ahead of Postgres. Postgres and MongoDB have been trading blows for the last five years here, both peaking in early 2020. But MongoDB declined faster in 2023 than Postgres. Neo4j and Cassandra decrease in lockstep. Couchbase barely hovers above zero.
I used two queries to get the number of monthly questions below because putting all in one query timed out. You can run them in the StackExchange Data Explorer.
(Click to expand) Query 1: MongoDB, MySQL, and Postgres
DECLARE @StartDate DATE = '2009-01-01';
DECLARE @EndDate DATE = '2023-12-31';
WITH TaggedQuestions AS (
SELECT
Id,
CreationDate,
CASE WHEN CHARINDEX('<mysql>', Tags) > 0 THEN 1 ELSE 0 END AS MySQLTag,
CASE WHEN CHARINDEX('<postgresql>', Tags) > 0 THEN 1 ELSE 0 END AS PostgresTag,
CASE WHEN CHARINDEX('<mongodb>', Tags) > 0 THEN 1 ELSE 0 END AS MongoDBTag
FROM PostsWithDeleted
WHERE
PostTypeId = 1 AND
CreationDate >= @StartDate AND
CreationDate <= @EndDate
),
MonthlyCounts AS (
SELECT
DATEADD(month, DATEDIFF(month, 0, CreationDate), 0) AS Month,
SUM(MySQLTag) AS MySQL,
SUM(PostgresTag) AS Postgres,
SUM(MongoDBTag) AS MongoDB
FROM TaggedQuestions
GROUP BY DATEADD(month, DATEDIFF(month, 0, CreationDate), 0)
)
SELECT
Month,
MySQL,
Postgres,
MongoDB
FROM MonthlyCounts
ORDER BY Month;
(Click to expand) Query 2: Cassandra, Couchbase, and Neo4j
DECLARE @StartDate DATE = '2009-01-01';
DECLARE @EndDate DATE = '2023-12-31';
WITH TaggedQuestions AS (
SELECT
Id,
CreationDate,
CASE WHEN CHARINDEX('<neo4j>', Tags) > 0 THEN 1 ELSE 0 END AS Neo4jTag,
CASE WHEN CHARINDEX('<cassandra>', Tags) > 0 THEN 1 ELSE 0 END AS CassandraTag,
CASE WHEN CHARINDEX('<couchbase>', Tags) > 0 THEN 1 ELSE 0 END AS CouchbaseTag
FROM PostsWithDeleted
WHERE
PostTypeId = 1 AND
CreationDate >= @StartDate AND
CreationDate <= @EndDate
),
MonthlyCounts AS (
SELECT
DATEADD(month, DATEDIFF(month, 0, CreationDate), 0) AS Month,
SUM(Neo4jTag) AS Neo4j,
SUM(CassandraTag) AS Cassandra,
SUM(CouchbaseTag) AS Couchbase
FROM TaggedQuestions
GROUP BY DATEADD(month, DATEDIFF(month, 0, CreationDate), 0)
)
SELECT
Month,
Neo4j,
Cassandra,
Couchbase
FROM MonthlyCounts
ORDER BY Month;
Please note that the overall monthly number of Stack Overflow questions is down 55% since ChatGPT appeared (November 2022 vs. March 2024):

You can run the query below at the StackExchange Data Explorer.
(Click to expand) Query 3: All Questions
DECLARE @StartDate DATE = '2009-01-01';
DECLARE @EndDate DATE = '2024-03-31';
WITH Questions AS (
SELECT
Id,
CreationDate,
1 AS AQuestion
FROM PostsWithDeleted
WHERE
PostTypeId = 1 AND
CreationDate >= @StartDate AND
CreationDate <= @EndDate
),
MonthlyCounts AS (
SELECT
DATEADD(month, DATEDIFF(month, 0, CreationDate), 0) AS Month,
SUM(AQuestion) AS Questions
FROM Questions
GROUP BY DATEADD(month, DATEDIFF(month, 0, CreationDate), 0)
)
SELECT
Month,
Questions
FROM MonthlyCounts
ORDER BY Month;
Analysis
SQL or NoSQL?
When picking a database, we must first decide whether to use a relational database (SQL) or one that foregoes said relations (NoSQL). Relational databases have been around for 40 years. They are trusted workhorses, and we know their strengths and weaknesses. NoSQL is the new kid on the block. So, what does it offer that relational databases don’t?
I’ve never used NoSQL in production. So here’s my outside view of the NoSQL advantages. Please correct me if I’m wrong!
Schemaless
We don’t define tables ahead of time. We just start saving our objects. If we add new properties to our classes, we just save them, which changes our database.
No joins
Database normalization is a best practice in relational databases: We keep our tables separate, link them with foreign key relationships, and query them with joins. An example is an order table in an online shop with a customer_id column that links it to our customer table. So far, so good. But when our tables have many records, table joins can be slow or sometimes even impossible. It’s my understanding that with NoSQL, there are no joins, and you embed duplicate data from the joined table into your original table. In other words, denormalization.
Better scaling
When your relational database gets too big for a single server, or that server isn’t fast enough, or you want redundancy, then things get hairy in the relational world: You use sharding to split your data across servers, or you set up database clusters for fail-over and redundancy. None of this is part of the relational model, so it differs from database to database. And running a database cluster with multiple main nodes that our applications can write to is tricky to set up. Not so with NoSQL databases: They were designed to scale, or so they say, and all of this is a lot easier.
Again, with just little production experience in NoSQL, I’ve got issues with two of these advantages.
Schemaless
When adding new columns to tables, the ALTER TABLE statement is the least of our problems in my experience. The more significant issue is: How do I fill these new columns meaningfully for my existing data? Let’s say we add a date_of_birth column to a customer table. The default value is probably null. So, how do I get the date of birth for all my existing customers? I don’t see how this is getting easier with NoSQL: I still only have one default for my new dateOfBirth property, and I similarly need to somehow get the date of birth for the existing customers.
Still, if we want schemaless in our relational databases, we can also get (most of) that: MySQL has a JSON datatype, as does Postgres.
No joins
Joins don’t work well - or not at all - if we have a lot of records. This means that if we don’t have many records, then joins work just fine. And it seems to me that we can denormalize data just as well in our relational database: We can duplicate the customer columns in the order table if we want to.
The data duplication in NoSQL databases and in denormalized relational ones has side effects, too: If we have properties/columns with customer data in a couple of classes/tables, then we need to update all of them in addition to our main customer class/table when customer data changes.
I’ve also heard that with NoSQL databases, we need to know how we’ll use the data and how we’ll query it before we start storing data. I suppose that’s because of the “no joins” duplication of data. But that doesn’t make much sense to me: Can’t we simply duplicate customer data into our order class after we created the order class? Isn’t the schemaless nature of NoSQL making that especially easy?
To me, the one clear advantage of NoSQL databases over relational databases is better scalability. So, if we have a ton of data, NoSQL databases work better because they were designed for that use case.
Now, not all is lost for the relational database fans among us. If you want to host your own database server, then a product like CockroachDB is right for you: A NoSQL database that acts as a relational database on the outside. In the case of CockroachDB, it behaves like Postgres, minus features like stored procedures, triggers, and such. If you need your database in the cloud, vendors like Amazon, Google, and Microsoft are happy to scale relational databases for you.
Assessment
So here’s my assessment of the candidates:
- There was a time when MySQL was synonymous with “database on the internet”. After all, MySQL was the “M” in “LAMP stack”, the dominating architecture for hosting websites in the early 2000s. It’s still the most popular database but has declined significantly. Being bought by Sun and then Oracle didn’t do MySQL any favors. Neither did the free fork MariaDB, created by one of the MySQL founders.
- Postgres has always played second fiddle to MySQL. And that for a database that defines itself as the “the World’s Most Advanced Open Source Relational Database”! But Postgres does have the image of being more sophisticated than MySQL. What it does have for sure is the concept of extensions that can safely add new functionality.
- MongoDB is the most popular NoSQL database on this list.
- I don’t know much about Cassandra, Couchbase, and Neo4j, except that they are much less popular than MongoDB (and decreasing) and, besides Cassandra, are barely mentioned in job ads.
This is my recommendation:
- On your current project, keep your existing database unless that database is absolutely, irrevocably, really not working out for you.
- If you need to switch databases or are on a new project:
- If you know that you’ll need the NoSQL features and/or scalability, and you can’t get this with MySQL, then use MongoDB.
- Otherwise, use MySQL.
Next Issue
The next issue will arrive in June 2024. Subscribe to it as a newsletter to have it in your inbox then!